Motubrain: A World Action Model
Unified World–Action Modeling
A single model jointly represents video and action, allowing VLA policy modeling, world modeling, video generation, inverse dynamics, and joint video-action prediction to emerge as different inference modes within the same framework.
From Action Fitting to World Understanding
By jointly modeling the video-action distribution, the model learns more than a mapping from observations to actions. Instead, it acquires shared world knowledge that captures relationships among tasks, environmental changes, and action consequences.
Heterogeneous Data Absorption Capability
Unified modeling enables the model to simultaneously utilize video-only data, task-agnostic data, and complete robot trajectories, thereby overcoming the limitations of traditional VLAs that rely exclusively on robot-specific task trajectories.
Three-Stream Language–Action–Video MoT with Multi-Foundation-Model Integration
Through MoT, the model integrates the priors of video generation models, language models, and action models, enabling simultaneous acquisition of dynamic world understanding, semantic reasoning, and action generation capabilities.
Positive Multi-Task Scaling
As the number of tasks increases, the amount of shared world knowledge learned by the model also grows, leading to higher average success rates. This demonstrates that unified modeling captures transferable cross-task regularities rather than task-specific action patterns.
Extending the Paradigm — Motubrain
Building upon Motus, Motubrain further advances the framework in several key directions:
- Supports unified multiview modeling with arbitrary camera configurations, removing dependence on fixed visual inputs.
- Introduces an independent language stream that bridges high-level semantics and low-level control, allowing language instructions to directly participate in action generation for more reliable execution of complex tasks.
- Adopts a unified action representation across embodiments, enabling the model to learn transferable control principles rather than embodiment-specific action formats and thereby support rapid adaptation to new robotic platforms.
- Combines autoregressive Teacher Forcing with diffusion-based action generation to support long-horizon task memory and real-time closed-loop control, enabling the execution of task sequences involving more than ten atomic actions without VLM text memory.
- Leverages large-scale embodied-model inference optimization, Video-to-Action (V2A) inference, and real-time closed-loop control to enable cloud-edge-device collaborative deployment and smooth real-time control of large embodied foundation models.
- These innovations enable Motubrain to rapidly adapt to new embodiments using only 50–100 demonstrations. Validated across multiple humanoid platforms, Motubrain can complete long-horizon tasks involving more than ten atomic actions with high success rates using only its native World Action Model—without VLM-based planning, dual-system architectures, external memory, reinforcement-enhanced data, or retry-specific datasets. It also supports bimanual execution of different tasks while understanding distinct objectives for each arm.
Architecture & Methodology
Pre-training
- Relative EEF is adopted as a unified action representation. Actions from different robots are represented as changes relative to the current end-effector state, enabling effective utilization of heterogeneous robot data and rapid cross-embodiment adaptation.
- An independent text stream is introduced, treating language instructions as a separate modality and enhancing the model's understanding of task semantics, procedural constraints, and instruction following.
- Images from different camera views are concatenated at the token level, and view-dependent RoPE offsets are used to distinguish camera perspectives. This enables unified modeling with arbitrary numbers of views and supports diverse robot and scene configurations.
- A noisy-conditioning strategy is adopted, where random Gaussian noise is added to conditioned frames with a probability of 50% during training, improving robustness to visual noise, observation disturbances, and state deviations encountered in real-world deployment.
- H-bridge attention is employed, where video-action joint attention is applied only in the middle Transformer layers. This preserves cross-modal interaction capabilities while reducing computational overhead and preventing excessive modality-specific noise.
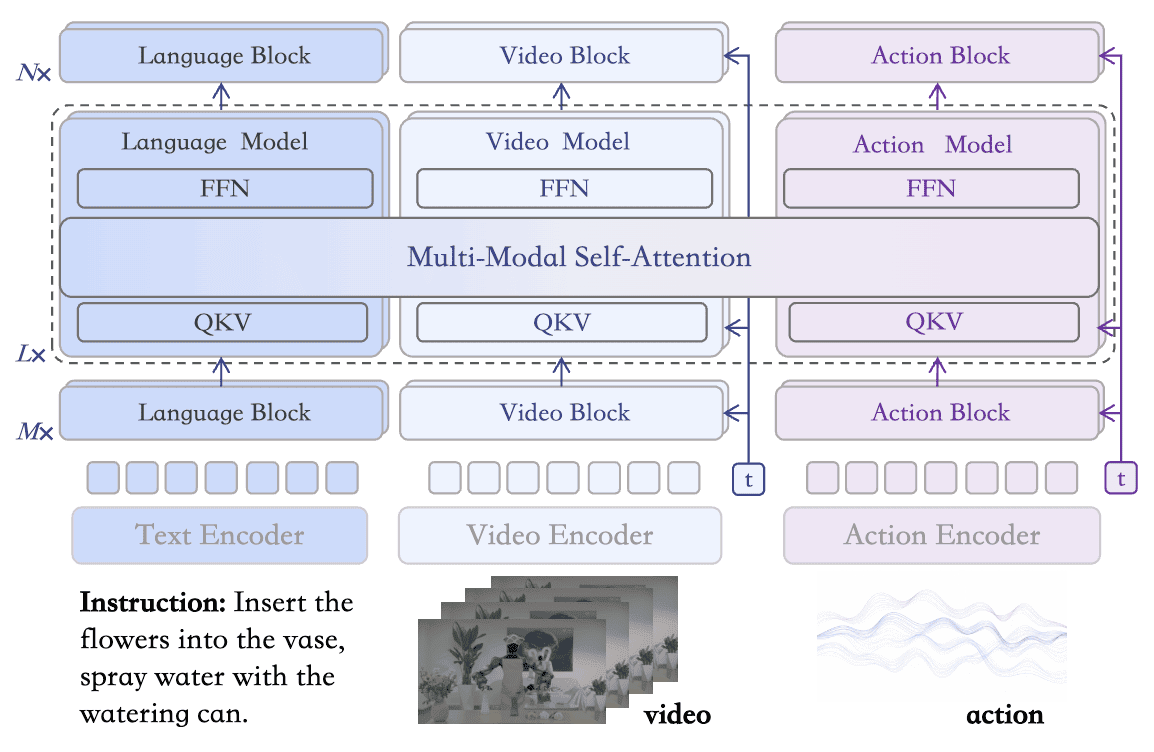
Post-Training & Inference
- Teacher-Forcing-based autoregressive training is combined with diffusion-based action generation, enabling the model to learn long-horizon dependencies and action continuity, thereby supporting real-time closed-loop control and multi-step task execution.
- By integrating DiT cache, FP8 quantization, CUDA Graphs, and other inference optimizations, the system achieves an inference frequency of approximately 5 Hz despite its large parameter count and computational requirements—roughly a tenfold speedup compared with Motus.
- Through IDM / Video-to-Action inference, the model no longer generates complete future videos during deployment and instead updates only the action branch. Combined with additional system-level optimizations, inference frequency can be further increased to 11 Hz, exceeding typical human reaction speed.
- Real-Time Chunking decomposes long action sequences into executable action chunks. Combined with action-smoothing strategies, this enables stable closed-loop control and smooth execution on real-world robots.

Results
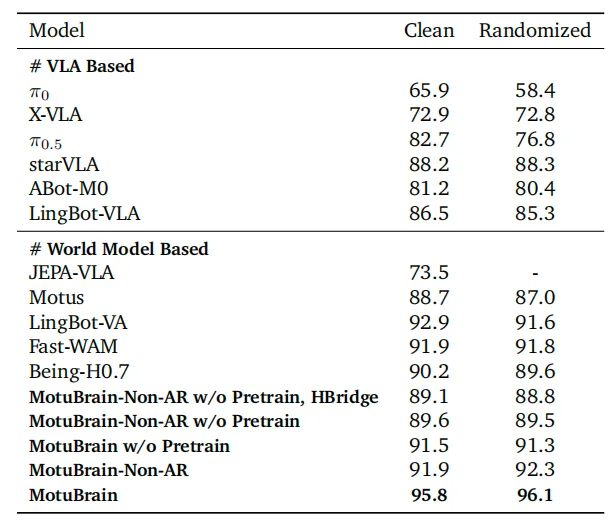
On the RoboTwin 2.0 benchmark for embodied action execution, Motubrain achieved scores of 95.8 and 96.1 in the Clean and Randomized settings, respectively, ranking first in both. It is the only model on the leaderboard with an average score above 95 under randomized evaluation and achieved perfect or near-perfect scores on most individual tasks. This demonstrates its capability to act effectively in the world.
Multi-task Generalization Scaling Curve: As the number of tasks increases, the amount of shared world knowledge across tasks grows, leading to higher average success rates. In contrast, VLA systems are more susceptible to interference among tasks.
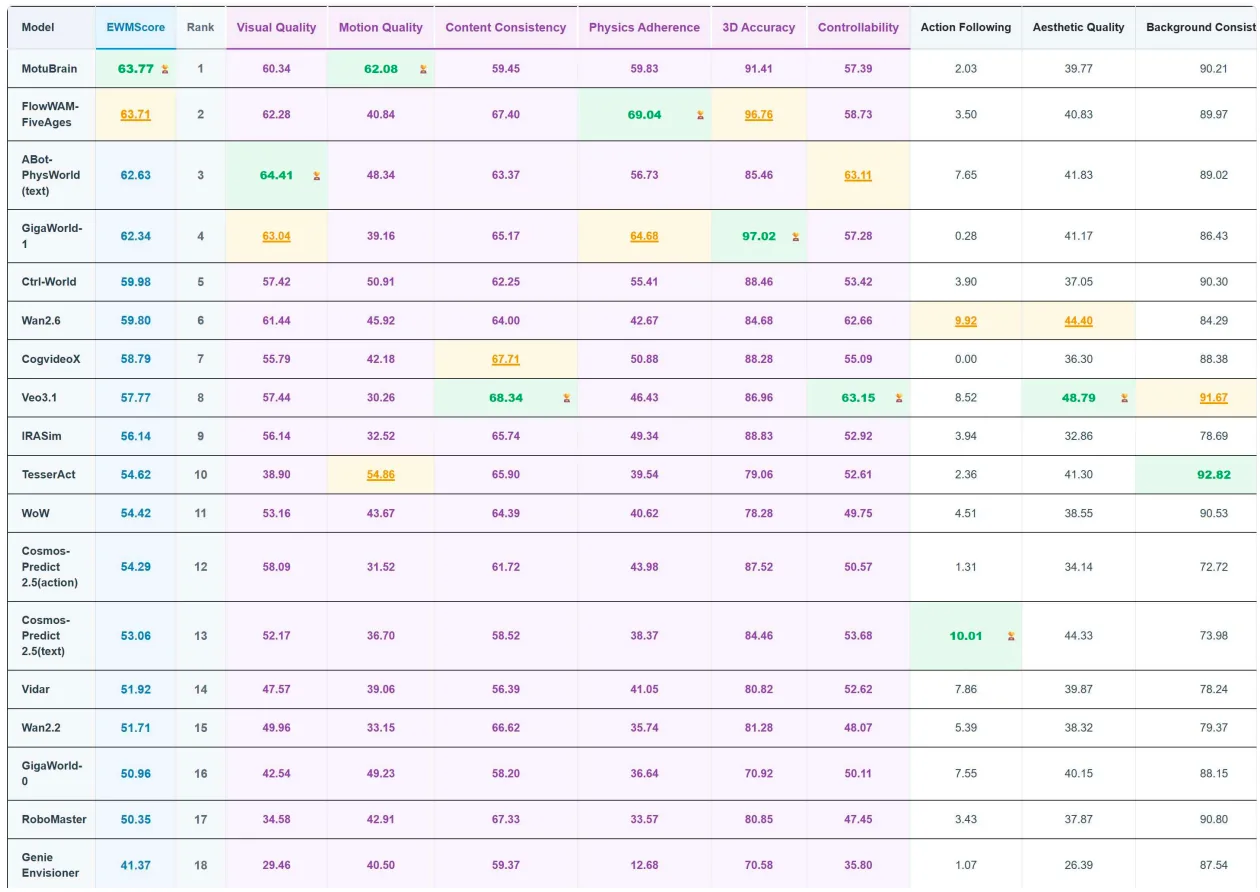
- On WorldArena, Motubrain also achieved first place. This benchmark evaluates whether a model can understand motion dynamics, accurately predict physical changes over time, and maintain awareness of environmental state transitions. This demonstrates its capability to predict and understand the world.
- In the CVPR 2026 RoboChallenge Table30v2 real-robot competition involving four robotic platforms, Motubrain achieved third place despite two robots not being evaluated under the optimal-model scoring setup, and it matched the success rate of the second-place system.
- Motubrain can rapidly adapt to new robot platforms using only 50–100 embodiment-specific demonstrations and has validated its deployment capability across multiple embodiments. Without relying on VLM planning, dual systems, external memory, reinforcement-enhanced data, or retry-specific data, Motubrain can complete complex real-world tasks with high success rates using only its native World Action Model.
Long-Horizon Task Execution Capability
Motubrain can complete task sequences involving more than ten atomic actions. For example, in a flower-arrangement task, the robot must insert flowers of different colors into a vase one by one. Although training data only cover a single vase and relatively fixed positions, the model can generalize to different vases, different placements, and interrupted execution scenarios. If a flower insertion fails or the flower is repositioned, the model adjusts its behavior based on the updated visual state rather than mechanically repeating the original trajectory.
Bimanual Coordination Capability
Motubrain can understand distinct task objectives assigned to the left and right arms and maintain coordination throughout execution. For example, in a combined pouring-water-and-picking-bread task, the training data typically involve simultaneous pouring and grasping. During inference, however, even when the robot must first finish pouring water before picking up the bread with one hand, the model correctly interprets pouring and bread picking as non-conflicting sub-goals and performs flexible bimanual collaboration.
Online Error-Correction Capability
Even without dedicated retry data or reinforcement-based training, Motubrain exhibits a degree of task retry and self-correction behavior. For example, in a meatball-scooping task, training demonstrations typically succeed on the first attempt. During real-world deployment, however, if the scoop misses the meatball on the first try, the model does not simply terminate the action. Instead, it attempts again, demonstrating an understanding of the task objective rather than merely replaying an action trajectory.
These experiments demonstrate that Motubrain learns more than single-step action imitation. It continuously makes decisions based on the current visual state, task objectives, and anticipated action consequences, thereby enabling long-horizon manipulation, bimanual coordination, and online adaptation after failures.